

This article Data Science Blogthon.
prologue
Hierarchical clustering is one of the most popular clustering techniques used in unsupervised machine learning. K-means and hierarchical clustering are two of the most popular and effective clustering algorithms. It is possible to provide such a high level of performance due to working mechanisms applied in the backend.

This article describes hierarchical clustering and its types, its mechanism of operation, its core intuition, the pros and cons of using this clustering strategy, and some basics to remember for this practice. put together. Knowledge of these concepts will help you understand the working mechanism and answer interview questions related to hierarchical clustering in a better and more efficient way.
Overview
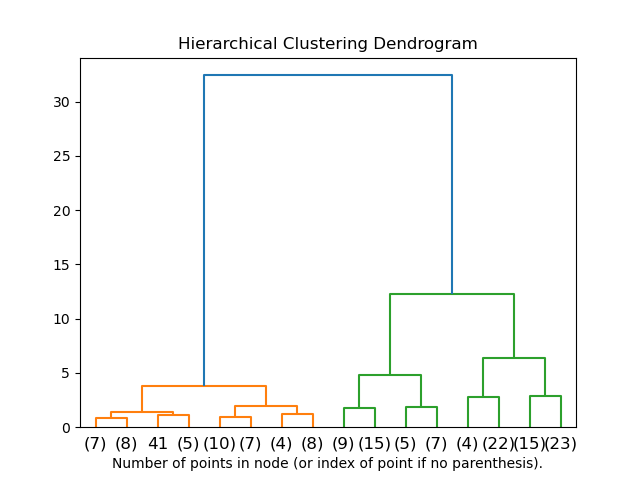
Hierarchical clustering is an unsupervised machine learning clustering strategy. Unlike K-means clustering, it uses a tree-like morphology to organize the dataset and a dendrogram to create a hierarchy of clusters.
Here, the dendrogram is a tree-like form of the dataset, where the X-axis of the dendrogram represents the features or columns of the dataset and the Y-axis of the dendrogram represents the Euclidean distance between data observations. .
import scipy.clusters.heirarchy
plt.figure(figsize=(11,7))
plt.title("Dendrogram")
dendrogram = schs.dendrogram(shc.linkage(data,method='ward'))
A typical dendrogram looks like this:
Types of hierarchical clustering
There are two types of hierarchical clustering:
- Agglomerative clustering
- divisive clustering
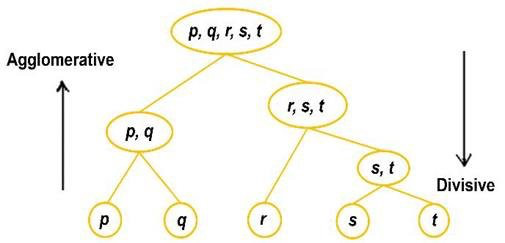
Agglomerative clustering
Each dataset is one specific data observation and a set of agglomerative clusterings. Based on the distance between groups, similar collections are merged based on the algorithm’s loss after one iteration. Loss values are again calculated in the next iteration and similar clusters are recombined. This process continues until the loss minimum is reached.
code
divisive clustering
Divisive clustering is the opposite of agglomerative clustering. The entire dataset is considered as one set and the loss is calculated. The entire single set is divided into multiple clusters according to the Euclidean distance and similarity between data observations in the next iteration, hence the name “dissociative”. This same process continues until the minimum loss value is reached.
There is no way to implement split clustering in Sklearn, but you can do it manually using the code below.
Importing Required Libraries
import numpy import pandas import copy import matplotlib.pyplot from ditsance_matrix import distanceMatric
Creating the Diana class
Class DianakClustering:
def __init__(self,datak):
self.data = datak
self.n_samples, self.n_features = datak.shape
def fit(self,no_clusters):
self.n_samples, self.n_features = data.shape
similarity_matrix = DistanceMatrix(self.datak)
clusters = [list(range(self.n_samples))]
while True:
csd= [np.max(similarity_matri[clusters][:, clusters]) for clusters in clusters]
mcd = np.argmax(cd)
max_difference_index = np.argmax(np.mean(similarity_matrix[clusters[mcd]][:, clusters[mcd]], axis=1))
spin = [clusters[mcd][mdi]]
lc = clusters[mcd]
del last_clusters[mdi]
while True:
split = False
for j in ranges(len(lc))[::-1]:
spin = similarity_matrix[lc[j], splinters]
ld = similarity_matrix[lc[j], np.delete(lc, j, axis=0)]
if np.mean(sd) <= np.mean(lc):
spin.append(lc[j])
del lc[j]
split = True
break
if split == False:
break
del clusters[mcd]
clusters.append(splinters)
clusters.append(lc)
if len(clusters) == n_clusters:
break
cluster_labels = np.zeros(self.n_samples)
for i in ranges(len(clusters)):
cl[clusters[i]] = i
return cl
Run the code below using the data.
if __name__ == '__main__':
data = pd.read_csv('thedata.csv')
data = data.drop(columns="Name")
data = data.drop(columns="Class")
dianak = DianaClustering(data)
clusters = dianak.fit(3)
print(clusters)
loss function in clustering
Most clustering methods can use the silhouette score to compute the loss for a particular clustering algorithm. Compute the silhouette score using two parameters: cohesion and splitting.
Cohesion corresponds to the similarity between two observations from the data. where b is the distance or difference between two observations from the data. For all data observations in the set, we compute cohesion (a) and splitting (b), noting each observation in the dataset.
the formula of silhouette score teeth:
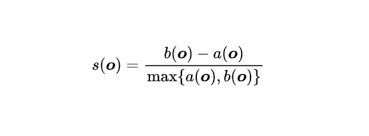
Hierarchical clustering vs KMeans
The difference between Kmeans and hierarchical clustering is that in Kmeans clustering the number of clusters is predefined, denoted by ‘K’, whereas in hierarchical clustering the number of sets is either one or approximately the number of data observations. Is the same.
Another difference between these two clustering methods is that K-means clustering is more effective for much larger datasets than hierarchical clustering. However, the hierarchical clustering spheroid forms a small dataset.
K-means clustering is more effective on the dataset spheroidal shape of clusters compared to hierarchical clustering.
advantage
1. Performance:
It works well for observing data from data shapes and returns accurate results. Unlike KMeans clustering, the good performance here is not restricted to the spheroidal shape of the data. Hierarchical clustering can use data with arbitrary values.
2. Easy:
Ease of use and great community support to provide better user guidance. It has a great amount of content and excellent documentation to improve your user experience.
3. Other approaches:
There are two approaches, agglomerative and split, using which datasets can be trained and tested. So if the provided dataset is complex and very difficult to train, another approach can be used.
4. Performance on small datasets:
Hierarchical clustering algorithms are effective on small datasets, reduce training and testing time, and return accurate and reliable results.
Cons
1. Time complexity:
Hierarchical clustering has a high time complexity due to the many iterations and computations involved. In some cases, that’s one of the main reasons I prefer KMeans clustering.
2. Space complexity:
The space complexity of the algorithm is very high because many computations of lossy error are associated with every epoch. For this reason, model space is taken into account while implementing hierarchical clustering. In such cases, prefer KMeans clustering.
3. Poor performance on large datasets:
When training hierarchical clustering algorithms on large datasets, the training process takes too much time and the performance of the algorithms suffers.
This article uses a mathematical formulation to explain the most powerful concepts associated with hierarchical clustering algorithms and their core intuitions and working mechanisms. Knowledge of these concepts will help you understand them better. It helps answer questions related to hierarchical clustering that are asked in data science interviews very efficiently.
The main points of this article are:
1. It works well for small datasets, but does not work well for large datasets and spheroidal shapes of datasets.
2. Hierarchical clustering is computationally intensive and therefore has a very high spatial and temporal complexity.
3. Dendrograms are an integral part of hierarchical clustering, and silhouette scores are used to compute errors in clustering algorithms.
Test your hierarchy skills by reading the top 20 questions here.
Media shown in this article are not owned by Analytics Vidhya and are used at the author’s discretion.