

This article data science blogthon.
prologue
K-Nearest Neighbors is one of the most popular and best-performing algorithms in supervised machine learning. Moreover, the KNN algorithm is the most widely used algorithm among all other algorithms developed for its speed and accurate results. Therefore, data science interviews sometimes ask detailed questions about the k nearest neighbors. This article discusses and solves advanced interview questions related to k-nearest neighbors in machine learning.

1. Why is the time complexity so high in KNN’s prediction phase?
In almost all machine learning algorithms, the algorithm first trains on training data and then makes predictions based on a pre-prepared dataset. K-Nearest Neighbors is a machine learning clustering algorithm that divides the training data into a certain number of clusters by calculating the distance of certain points from other points.While predicting then cautious obesity
There are two machine learning algorithms. learn When eager learningLazy learning is a machine learning algorithm that does not train on the provided training data. Instead, when a query is created to predict the algorithm is trained only on the training dataset. In an eager learning algorithm, the algorithm tries to teach training data as it is provided. Then, when a new query is made for prediction, the algorithm bases its predictions on previous data training. The K nearest neighbors also store the training data. Then, when there is time for the prediction phase, the algorithm calculates the distances between the query point and other points and tries to assign clusters to specific topics. So it only trains data when the system is queried. This is why it is known as a delayed learning algorithm.
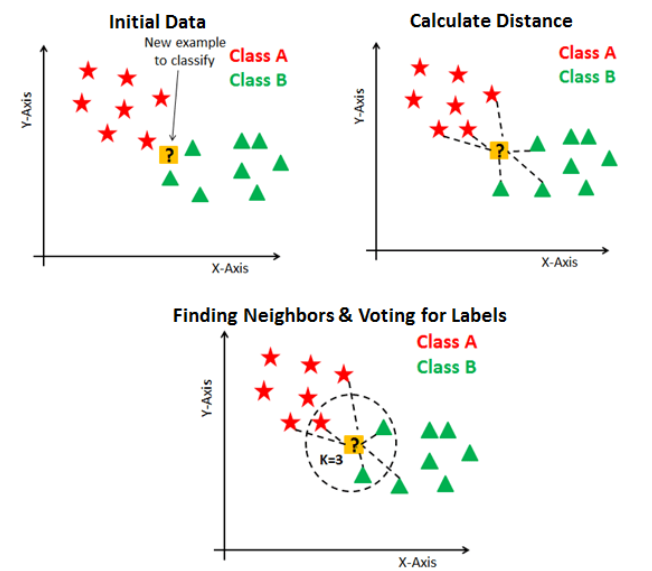
- Delayed learning algorithms store data, so they require more space. So KNN needs more space to store.
- The reason behind the speed of KNN is that training on KNN is very fast because you don’t train on the training data.
- Because KNN trains on training data during the prediction stage, KNN algorithms tend to make predictions very slowly.
2. Why is the KNN algorithm said to be more flexible?
K Nearest Neighbors is a nonparametric algorithm that makes no major assumptions during training and testing on datasets. Parametric machine learning algorithms such as linear regression, logistic regression, and naive Bayes make a key assumption that the data must be linear or the dataset is free of multicollinearity. Because of this, some algorithms can be more flexible. We can only use them if the assumptions they made are met. For example, linear regression cannot be applied if the data are not linear. Naive Bayes is not applicable when the dataset has multicollinearity.
But for the KNN algorithm, because it is a nonparametric algorithm, it makes no major assumptions about the dataset, so it can be applied to any dataset and returns good results. This is the main reason behind the KNN algorithm’s flexibility.
3. Why is the KNN algorithm less efficient than other machine learning algorithms?
KNN is best suited for problem statements when flexibility is a priority, but it also suffers from efficiency drawbacks. Suppose you want the efficiency of a particular model. In that case, KNN is not a very efficient machine learning algorithm compared to various machine learning algorithms, so other available algorithms should be used. Since KNN is a delayed learning algorithm, it typically saves input or training data and does not train while rain data is being fed.
Instead, it trains when the query for prediction is made. This is the main reason behind the time complexity of the prediction phase. On the other hand, some eager learning algorithms, such as linear regression, train on training data on the fly and make predictions on the data very fast. For this reason, KNN is said to be less efficient than other machine learning algorithms.
4. Why does KNN work well on normalized datasets?
Nearest Neighbors in K is a distance-based machine learning algorithm that is known to compute the Euclidean distance between points and return an output. No, in some cases the features in your dataset may have very different scales. In that case the distance between the points will also be very long or very short. This leads to erroneous and noisy data in the Euclidean length. So the algorithm doesn’t work well. For example, I have an individual age and salary dataset. Currently, age varies from 0 to 99 and salaries can be in the hundreds of thousands or billions of rupees. So here it also affects the Euclidean distance as the scale is very different between her two features. So if your data is not normalized, your algorithm will perform poorly. If the data is normalized, then all values will be between 0 and 1. So calculating the Euclidean distance on data of the same scale is very easy for the algorithm and thus the model works well.
5. Can small values of K cause overfitting in the KNN algorithm? Explanation.
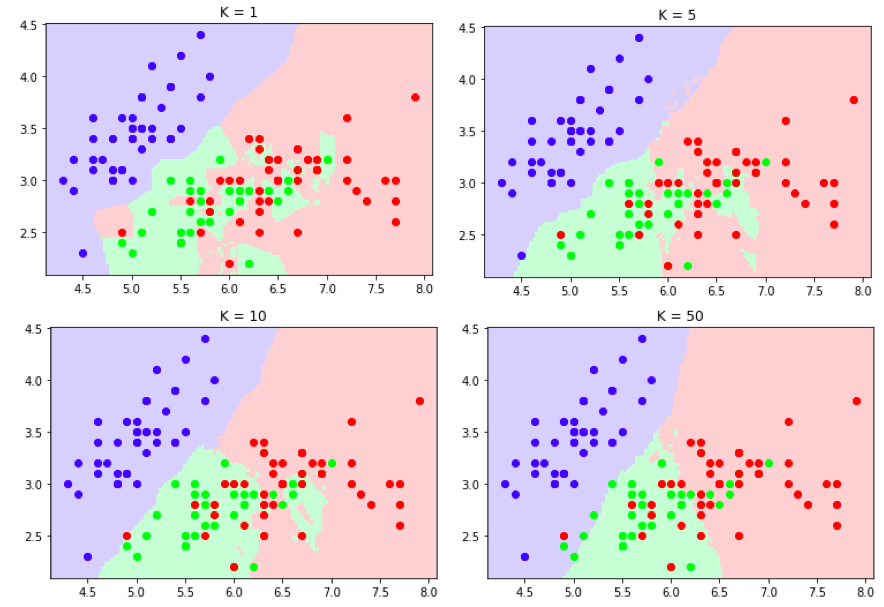
On the other hand, very high values of K produce fewer clusters and degrade model performance. Underfitting causes the model to perform poorly in training and testing on both data.
In this article, we discussed advanced interview questions related to k nearest neighbors and their solutions, including the core intuition and rationale behind them. Knowledge of these concepts will help you answer these tricky and varied questions efficiently.
A few important point From this article:
2. The time complexity of KNN is low during the training phase and high during the testing phase. This is because the training phase is a delayed learning algorithm that doesn’t do any computations. The spatial complexity also follows the same trend as the temporal complexity of the KNN algorithm.
3. KNN is a nonparametric machine learning algorithm that offers more flexibility and less efficiency. Being a nonparametric algorithm, it has no assumptions like linear regression.
Media shown in this article are not owned by Analytics Vidhya and are used at the author’s discretion.