

prologue
The duck was chosen as the mascot for this database management system (DBMS) because it is a very versatile animal that can fly, walk, and swim. In other words, it is designed as her DBMS for local analysis. Now let’s see what features it offers.
- easy installation
- Embedded: no server management
- Processing and storing tabular datasets (such as CSV and Parquet files)
- Single file save format
- High-speed analytical processing
- Fast transfer between R/Python and RDBMS
- Interactive data analysis, e.g. joining and aggregating multiple large tables
- Simultaneous large changes to multiple large tables such as adding rows, adding/deleting/updating columns
So let’s see what we can learn in this article.
what will you learn
In this article, you’ll learn how to install DuckDB, import, read and write CSV and Parquet files, meta queries, and the DBeaver SQL IDE. in short:
- getting started
- Import and export of CSV and parquet files
- meta query
- DBeaver SQL IDE
Get started with DuckDB
Enough talk. Now let’s get our hands dirty with the code 😉
Install DuckDB on your system.
Import the database and connect.
Ok, but I don’t always create the files manually. I need to read (or write) some files. The famous CSV, isn’t it?
In the next section you will learn how to work with CSV to read and write in a very convenient and fast format. Ornate parquet.
File import and export
Let’s start with the data scientist’s best friend: the CSV file.
Load the CSV file into a table using the read_csv_auto function.
con.execute("SELECT * FROM read_csv_auto('my_local_file.csv')").df()
Create a new table.
con.execute("CREATE TABLE tbl AS SELECT * FROM read_csv_auto('my_local_file.csv')")
Export data from a table to a CSV file.
con.execute("COPY tbl TO 'my_export_file.csv' (HEADER, DELIMITER ',')")
If you haven’t been introduced to him yet, it’s time to meet him. Parquet files are essential when working with large amounts of data. I won’t go into detail about its benefits in this article, but at this point you can see how simple and easy it is to work with this file format in DuckDB.
Read a Parquet file into a table using the read_parquet function.
con.execute("SELECT * FROM read_parquet('my_local_file.parquet')").df()
Create a new table.
con.execute("CREATE TABLE tbl5 AS SELECT * FROM read_parquet('my_local_file.parquet')")
Export data from a table to a Parquet file.
con.execute("COPY tbl TO 'my_export_file.parquet' (FORMAT PARQUET)")
OK! But what about huge tables? Let’s talk about it in the next section!
meta query
It’s very convenient to create some tables and then list them all. You can do this with SHOW TABLES.
con.execute("SHOW TABLES").df()
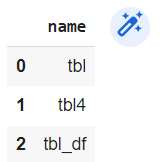
To see the schema of a table, use DESCRIBE followed by the table name.
df = pd.DataFrame({'Col1' : [100,90,30],'Col2' : [1,5,8]})
con.execute("CREATE TABLE tbl_df AS SELECT * FROM df")
con.execute(“DESCRIBE tbl_df”).df()

The most useful command in my opinion is SUMMARIZE. Returns the column name, column type, minimum value, maximum value, number of unique values, mean, standard deviation, quartile, number of values, and percentage of null values. A large amount of information with one command!
con.execute("SUMMARIZE tbl").df()

In practice, there is so much information that you may not need it or may find it difficult to see. For example, you can use the SUMMARIZE command in combination with SELECT to get a summary of just the desired columns.
con.execute("SUMMARIZE SELECT Col1 FROM tbl").df()

If you like SQL and Python, you should give DuckDB a try.
DBeaver SQL IDE
“DBeaver is a powerful and popular desktop SQL editor and integrated development environment (IDE). Available in both open source and enterprise editions. Visually explore the tables available in DuckDB and create complex queries. DuckDB’s JDBC connector Allows DBeaver to query DuckDB files and, by extension, any other files that DuckDB can access (like a parquet file)”
If you like DubkDB, you’ll love this IDE. It’s easy and lightweight. In this section we will install, connect and create a database in local memory. Create, read and save parquet files!
Let’s go! This tutorial will show you how to install the Windows version. download page.
You can select your preferred language at the beginning of the installation.

DBeaver Community:

next,[データベース]in the menu[新しいデータベース接続]Click.
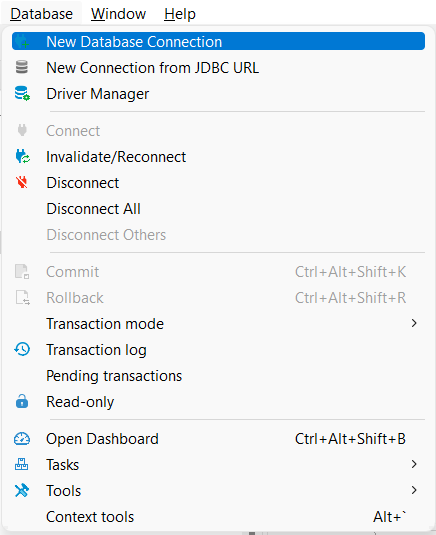
Which one do you think you will choose now? of course! It’s DuckDB.

You can enter “:memory:” for “Path” to start playing.
Click the “Test Connection…” button.

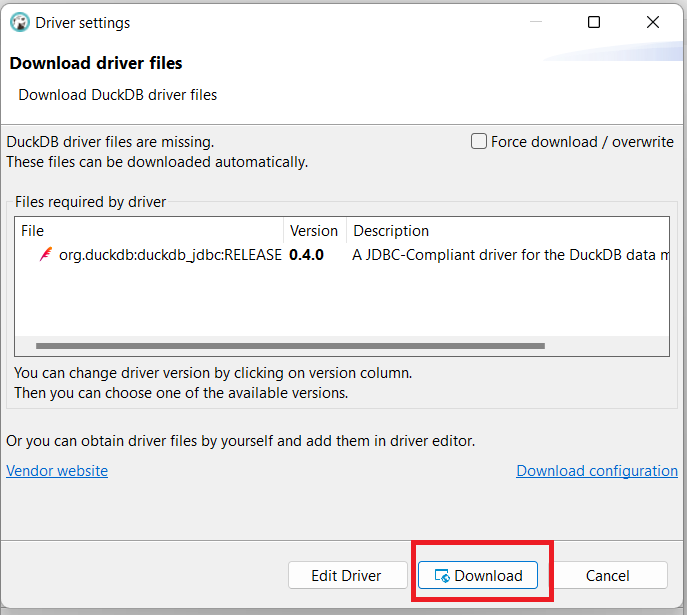
Click Download to download DuckDB’s JDBC driver from Maven. After the download is complete,[OK]Click[完了]Click.
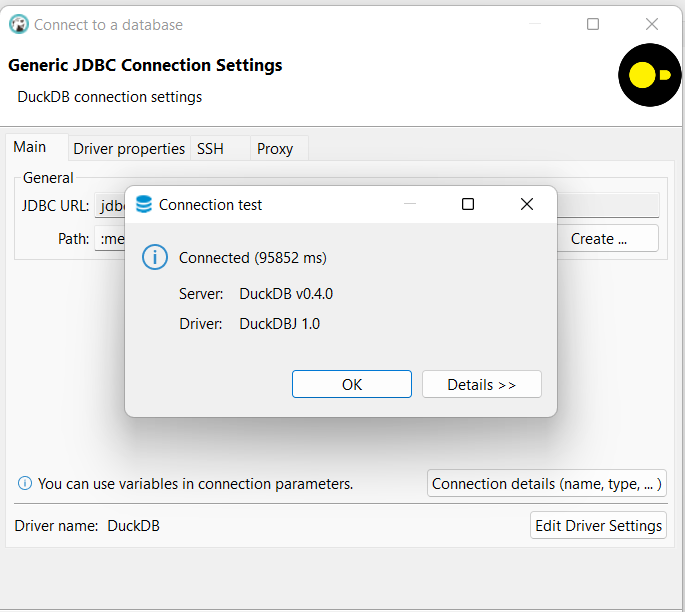
If you see this message, your connection was successful. Congrats!
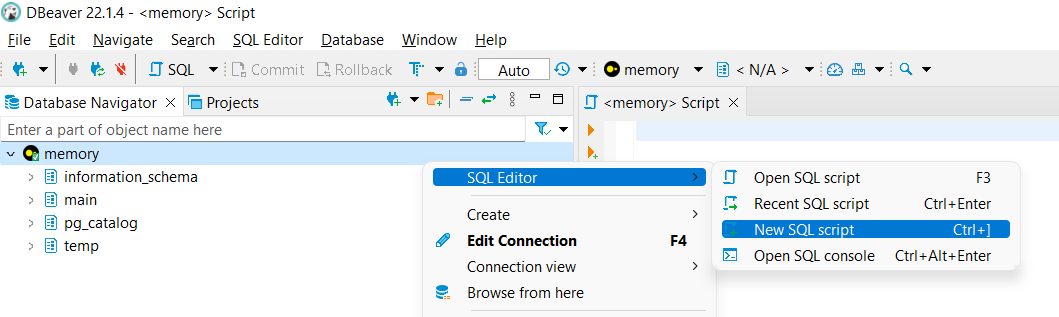
A key moment in “Hello World!” In DBeaver SQL IDE:
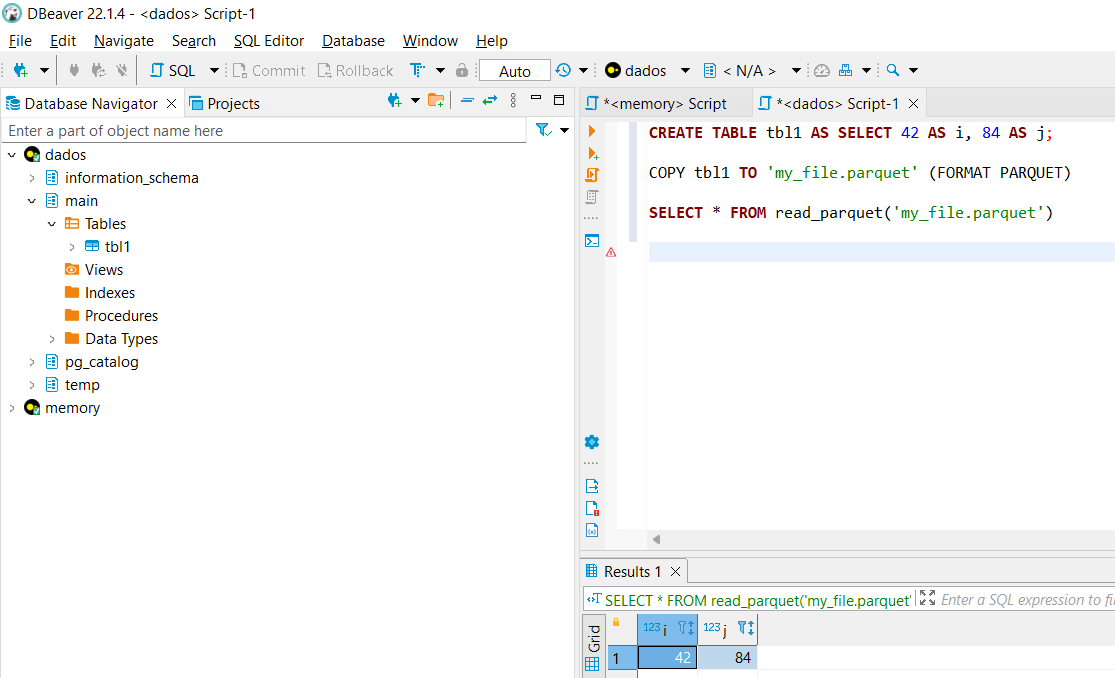
And finally the final moment! Create and write Parquet files.
In this article, you’ve learned how to get started with DuckDB, read and write CSV and Parquet files, summarize tables, and install and use the DBeaver Community SQL IDE.
Important points:
- Learn how to read and write CSV and Parquet files to help you with your daily practice.
- Now I also know how to display and summarize all tables.
- We know how an integrated development environment can help you organize all your work, so let me introduce you to the DBeaver SQL IDE.
Finally, I hope you have learned from this article. Feel free to leave us a friendly comment. Let’s meet again!
See the documentation at https://duckdb.org/ if you need additional information.