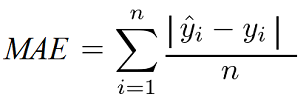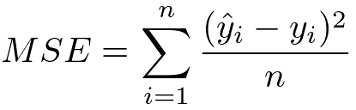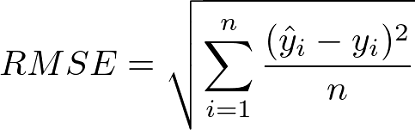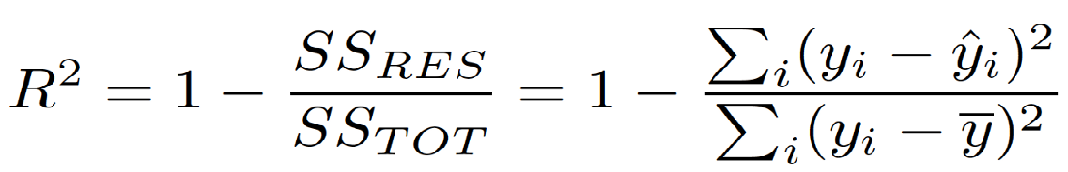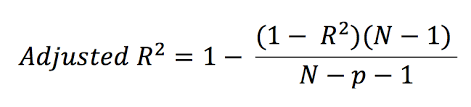The model is predicting positive and the actual value is also positive.
The video is predicted Kidsafe and is actually Kidsafe.
True Negative (TN):
The model is predicting negative and the actual value is also negative.
Video predicted not kid safe, actually not kid safe.
False Positives (FP):
The model predicted positive, but the actual value is negative.
These are also known as Type I errors.
The video is predicted to be Kidsafe, but not Kidsafe. May be violent or contain adult content not intended for children.
False Negatives (FN):
The model predicted a negative value, but the actual value is positive.
These are also known as Type II errors.
The video is predicted not to be kid-safe. Actually, it’s Kidsafe. It may be a cartoon, but it’s marked as violent.
Now let’s try to understand the different metrics.
1. Accuracy:
Accuracy represents the number of correctly classified data instances over the total number of data instances.
If the data is unbalanced, the accuracy will be skewed towards the classes with the highest counts, which is not a good metric.Choice of Precision or Recall
Accuracy = (TP + TN) / (TP + FP + FN + TN)
2. Accuracy:
How many correctly predicted cases turned out to be positive?
Useful when false positives are a primary concern over false negatives.
Accuracy should be as high as possible.
Accuracy = TP / (TP + FP)
3. Recall:
Also called sensitivity or true positive rate
Number of actual positive cases that the model correctly predicted
Useful when false negatives are more important than false positives.
Recall should be as high as possible.
Recall = TP / (TP + FN)
4. F1 Score:
This is the harmonic average of Precision and Recall.
The F1 score balances both precision and recall. If either is small, the F1 score will also be small. That’s the difference with precision.
How many actual negative cases can the model correctly predict?
Specificity = TN / (TN + FP)
6. AUC-ROC score:
Area Under the Curve – Abbreviation for Receiver Operating Characteristics.
ROC graphs are used to evaluate the performance of classification models against various thresholds.
AUC is a measure of a classifier’s ability to distinguish between classes.
When AUC = 1, the classifier perfectly distinguishes between classes.
0.5
For AUC=0.5, the classifier does not distinguish well between positive and negative classes.
Trade-off between accuracy and recall: Both Precision and Recall are expected to have high percentages. However, as we seek higher precision, recall decreases, and vice versa. Yuan. False positives are a concern at Youtube Kidsafe. You don’t want your children to see violent videos, but they may miss Kidsafe videos such as cartoons.
Regression metrics
1. Mean Absolute Error (MAE):
The mean absolute error is the sum of the predicted values minus the true value divided by the number of predicted values.
This metric is very useful when outliers are expected in the dataset.
2. Mean Squared Error (MSE):
The mean squared error is the sum of the squared differences between the predicted and true values divided by the number of predicted values.
3. Root Mean Square Error (RMSE):
Root mean square error is the square root of the sum of squared differences between the predicted values and the true values divided by the number of predicted values.
This evaluation metric is useful when outliers are expected in the dataset.
RMSE is larger than MAE if the dataset has many outliers.
4. R-squared:
R-Squared is a statistical measure of the proportion of the dependent variable’s variance explained by one or more independent variables in a regression model.
R-Squared is the residual sum of squares minus one divided by the total sum of squares.
R-Squared is used to find the best straight line goodness.
The problem with R-Squared is that adding new redundant variables does not reduce it. The R-Squared value stays the same or increases.
5. Adjusted R-squared:
Adjusted R-squared solves the problem by adding some independent variable (k) to the denominator.
The formula for adjusted R-squared is:
where N = number of data points in the dataset
p = number of independent variables.
Evaluation metrics are used to assess the correctness of the model. There are multiple metrics, but choosing the right one is important. A key factor in your selection is the type of data and problem you are trying to solve.
We hope this article helps you choose the right evaluation metric for your machine learning problem.
Media shown in this article are not owned by Analytics Vidhya and are used at the author’s discretion.
We're a provider of Data IT News and we focus to provide best Data IT News and Tutorials for all its users, we are free and provide tutorials for free. We promise to tell you what's new in the parts of modern life Data professional and we will share lessons to improve knowledge in data science and data analysis field.