

What is MMM (Marketing Mix Modeling)?
Marketing Mix Modeling uses advanced predictive analytics to evaluate marketing and media spend using the historical spend and results that it had generated in the past.
In marketing media agency or any organisation with larger media spend, it is vital to optimise the cost associated with ad spend.
The concept of Marketing Mix Modeling is a valuable topic for data scientists and marketing people. Most of the times predicting marketing budgets optimises ROI but it can also lead to better brand awareness and companies long term value.
In this article, I will demonstrate the main aim of MMM – Marketing Mix Modeling (MMM), methodology and actionable insights from the results.
These topics will further enhance your understanding of Marketing Mix Modeling and guide you through the process.
If you would want to fast forward to certain topics covered in the article, please find above the Table of Contents for easier read through of article.
Why do we use Marketing Mix Modeling?
Using Marketing Mix Modeling allows you to optimise ROI of marketing spend by understanding the contribution of sales in relation with marketing channel and the amount spent on that particular marketing channel at a particular time.
There is not always a linear relationship of marketing spend on a particular marketing and number of sales. It is usually non linear but that can be measured at high level by:
Sales=Sales from Digital Marketing (FB/Google/TikTok/Snap/Websites) + Sales from Non-Digital Marketing (TV/BillBoards/ShopFront/Print) + Sales from Non-Marketing (Brand Awareness/Value)
Or
Visits= Visits from Digital Marketing (FB/Google/TikTok/Snap/News Pages) + Visits from Non-Digital Marketing (TV/BillBoards/ShopFront) + Visits from Non-Marketing (Brand Awareness/Value)
What is primary goal for Marketing Mix Modeling?
Marketing Mix Modeling’s primary goal is to be able to predict sales based on of marketing and non-marketing data. The first problem for a data scientist and a marketer is to clearly define the business problem. And in the case of Marketing Mix Modeling, it can be defined by ROI from different marketing channels, understand seasonal trends of particular adveritising channel or it could be simply understanding the fraction of sales contribute to which marketing channel and spend.
There could be a linear relationship with a particular channel but a non-linear relationship on another channel. For example, while I was running my start up. I noticed the effect of spend made the growth exponential but over time, it became logarthmic so it hit its tipping point, and it did not matter how much money I would spend on marketing.
How do we create Marketing Mix Model?
First step in creating marketing mix model is to get information from various different marketing channels. These are mainly sales measures from marketing and non-marketing efforts.
Second step in creating marketing mix model is to be able to understand the affect of non-marketing channels and brand value/awareness.
Thirdly understanding the various aspects of seasonality, growth or decline (trend) and randomness which cannot be explained that needs to be catered for.
There are various different books and examples that you can leverage which will allow you to create a great marketing mix model from Google and Databricks but I have also ran through an example of Kaggle dataset:
1) This pinterest shows various aspects of Marketing Mix, first you need to define some of the
2)Amazon books which contains great example on Marketing Mix Modeling
3) Dataset to practice: Kaggle
Firstly Understanding principles of Marketing Mix Modeling (MMM)?
Using a technique known as time series decomposition (an example could be STL – Seasonal trend using Loess), we first attempt to explain as much of our sales data as possible WITHOUT Marketing Mix Modeling marketing spends.
Time series decomposition is an attempt to explain our sales dataset by breaking it into different components. Time series decomposition is also used in an Anomaly detector.
Typically a time series caters for seasonal effect over a long period of time, one can define the seasonality effect whether it be 1 year, 2 years or monthly trend by defining period of 30 days. For example, if you are running a water park, you will certainly have a busy period during summer time and you should be able to cater for that.
Understanding effect of Seasonality, Trend and Randomness
The changes over time can be explained in various different ways, it can be explained by adding, multiplying and decaying effect.
The trend aspects caters for growth and this growth can be long term increase in demand due to product or brand awareness for example there was YoY increase in brand awareness for Apple iPhone from 2008 onwards which lead to a lot of its sales non-accounted for marketing efforts.
Loess is a methodology which touches on anomaly detection and figures out ups and downs and outliers (usually 2.5x of standard deviation of 99.5% data lies within the mean of dataset while catering for seasonality and trend affect).
The remainder component is simply what is left that cannot be explained with trend or seasonality. .
Types of decomposition models
There two type of decomposition models:
1) Additive = Trend + Seasonal + Random
2) Multiplicative = Trend * Seasonal * Random
After applying time series decomposition to the dataset above, we are left with the following three components below.
 Notice how if you add these three components together, the result is equal to our initial weekly sales.
Notice how if you add these three components together, the result is equal to our initial weekly sales.
For purposes of this demo, only decomposed dataset is used with additive side but in some instances a multiplicative decomposition could be the right approach.
Multiplicative decomposition could be the right approach depending on whether the seasonal variation is increasing over time (multiplicative additive will be used in that scenario).
The focus is usually on the remainder component. For example, In an anomaly detector, usually this is what is used a lot more. There could be different randomness for different marketing channels.
A good example will be a TV add played after a successful TV show at 8p.m. on Wednesday night but you would start to see the results of that over time and hence you cannot apply the same principle to an ad which is on Social media which usually calls for action.
MMM Example Explained
In this analysis, we attempt to measure the effects of marketing on our remainder component through an increasingly popular statistical approach as opposed to a purely analytical solution.
Regression is most commonly used approach to figure out a mathematical formula which tells you how much of the sale was from marketing channel vs non-marketing channel. A statistical approach explains the model in detail.
All of this aside, for the purposes of this article, it is important to remember at the heart of our analysis, we are now attempting to solve this equation:
Sales From Marketing =Sales From TV + Sales from BillBoards + Sales from Brochures/Print media + Sales from social Media + Sales from CPC + Sales from SEO + Sales from Influencers etc…
By allowing our model to iterate through various different solutions, one can statistically estimate the most likely effects of our different marketing spends! Our final model, of course, aims to “predict” sales. The more accurate our model is, the more faith we should have in our model components (ROI of marketing spends). So what does this model look like? In its simplest form, our model should be judged by the actual sales (blue line) compared to our model predicted sales (orange line) shown in the table below.
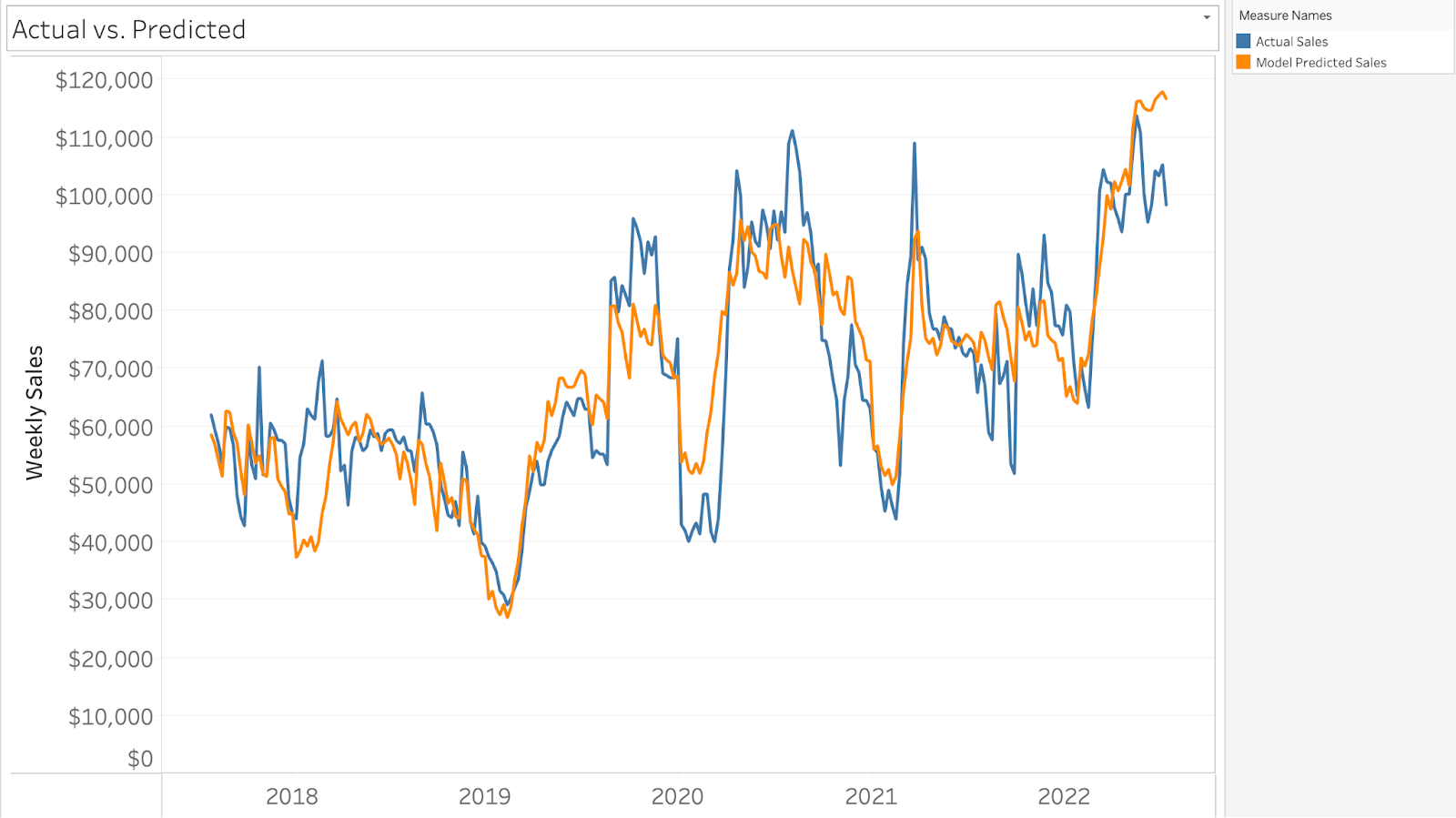
Some common ways to evaluate the quality of a regression model are to compare the actual vs. predicted values for a training and test set. We can do this by way of R Squared (R^2), Mean Absolute Error (MAE), Mean Absolute Percentage Error (MAPE), Root Mean Square Error (RMSE), and Normalized Root Mean Square Error (NRMSE) calculations.
| Model Evaluator | Value | Acceptable Value |
|---|---|---|
| R^2 | .87 | > .7 |
| MAE | $7,402 | N/A |
| MAPE | 11.4% | < 10% good, 10-25% acceptabl |
| RMSE | $9,677 | N/A |
| NRMSE | .11 | < .1 good, .1 – .25 acceptable |
The evaluations shown above are from in-sample comparisons only. In a more scrupulous evaluation, the same calculations would be applied to both a random holdout (random points in dataset) or last n data points (for example, holding out the last n months’ worth of data) to evaluate your model’s ability to predict future sales. A more in-depth analysis would also evaluate actual versus predicted ‘sales due to marketing.’
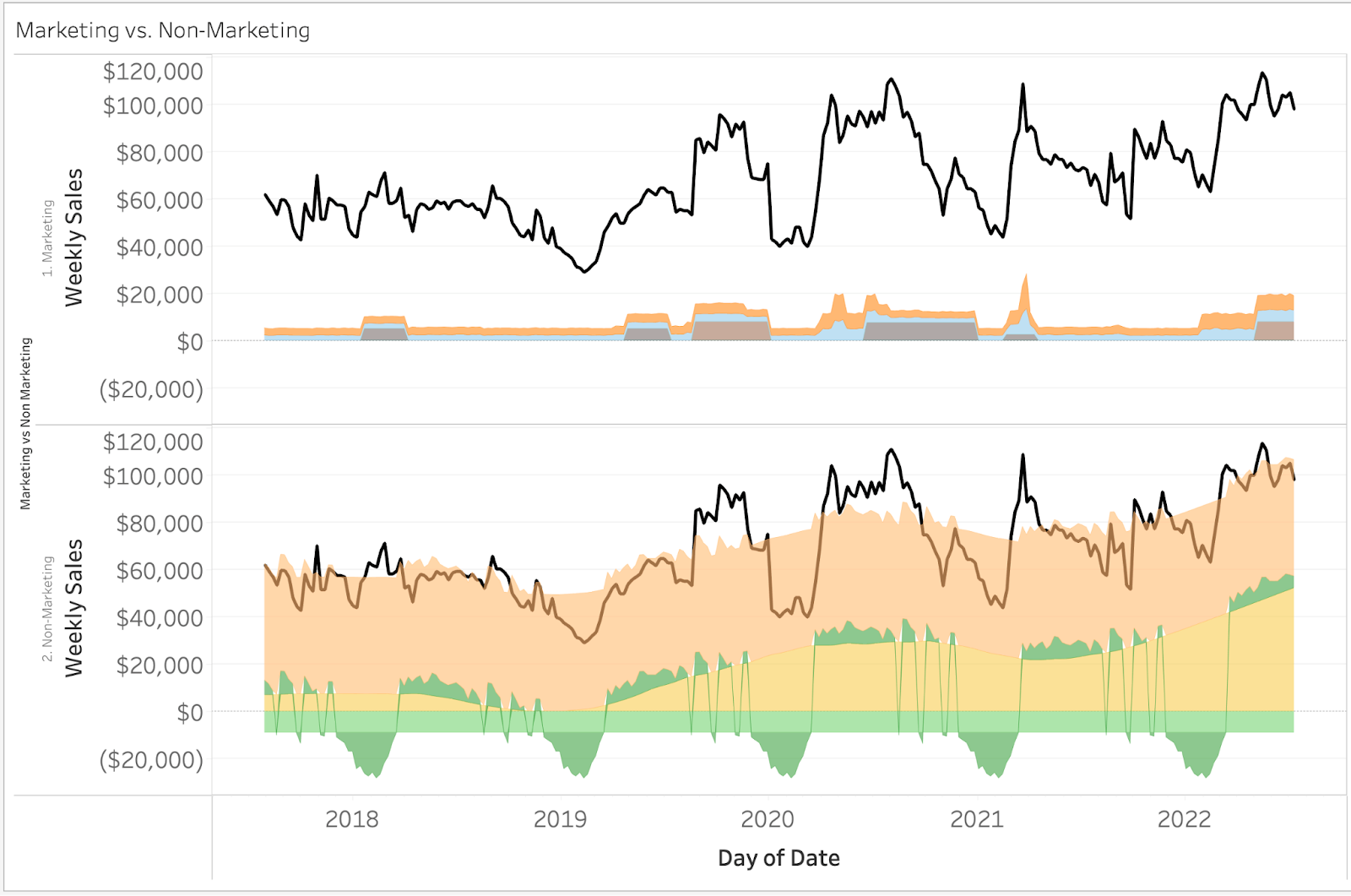
Now that we have established that our model has an acceptable level of accuracy, an obvious next question is “How much of our sales are due to marketing?” The visual below provides this information.
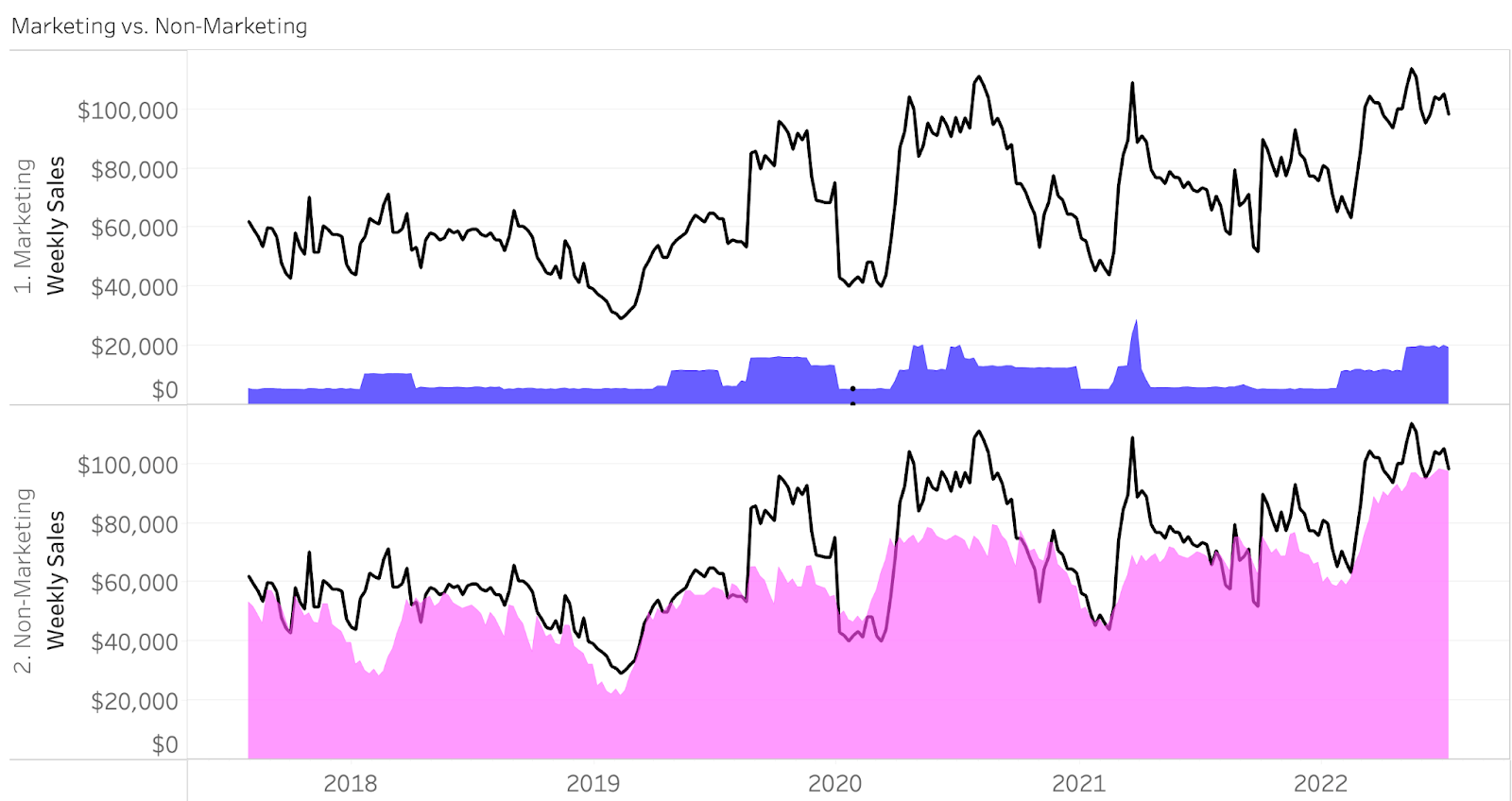
The black line in this plot is our actual sales, and the shaded areas represent model predicted sales due to Marketing and Non-Marketing. Another way to contextualize this would be what percentage of my total sales are due to marketing over time? (visualized below)
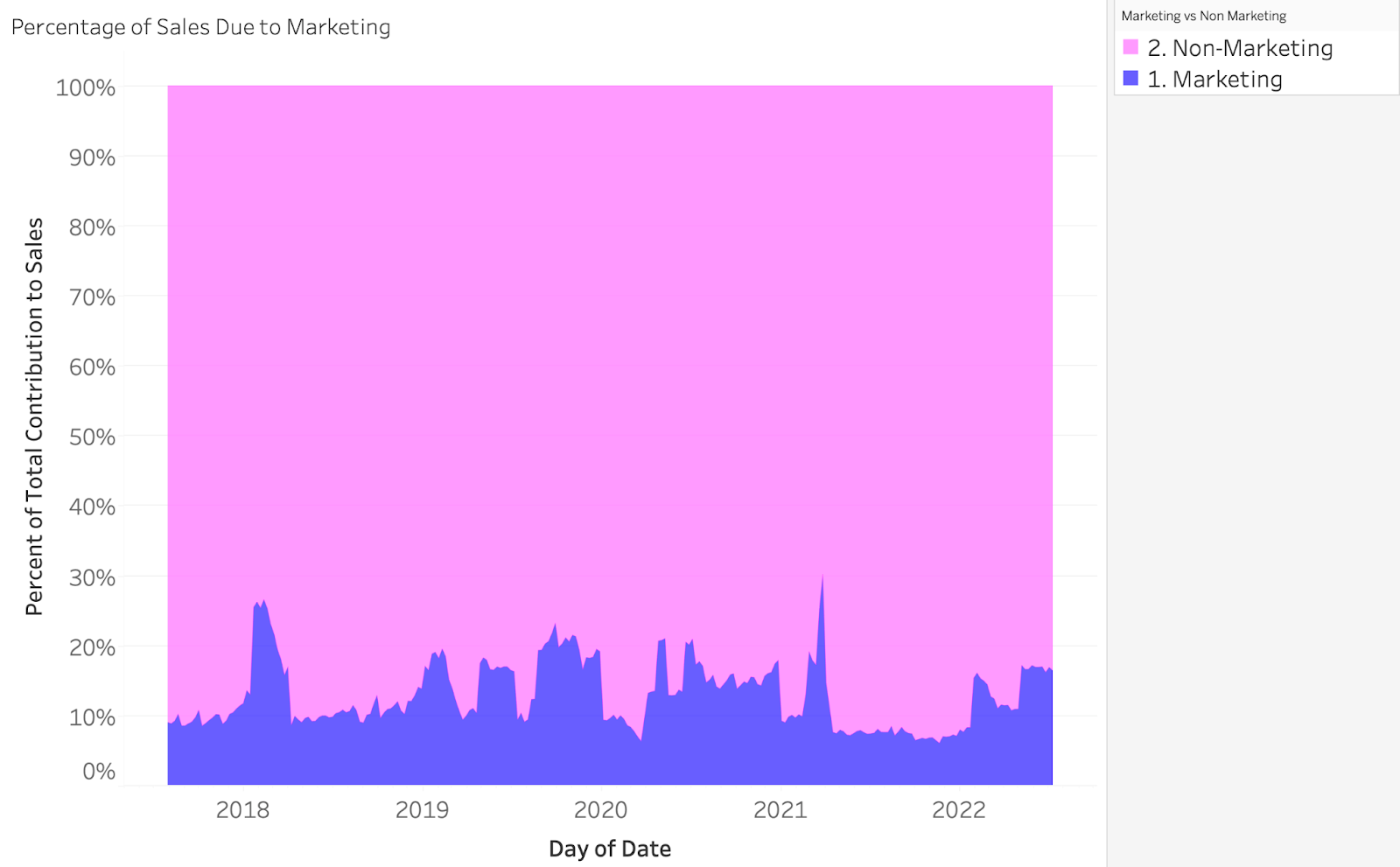
Our takeaway from this is that sales due to marketing, on average, represents around 10% of our total sales. In some extreme cases we estimate the effects of marketing to be upwards of 20-30%. This can be directly traced back to significant increases in our historical marketing budgets. In the cases of both Marketing and Non-Marketing sales, we can dive much deeper into the composition of our model (below).
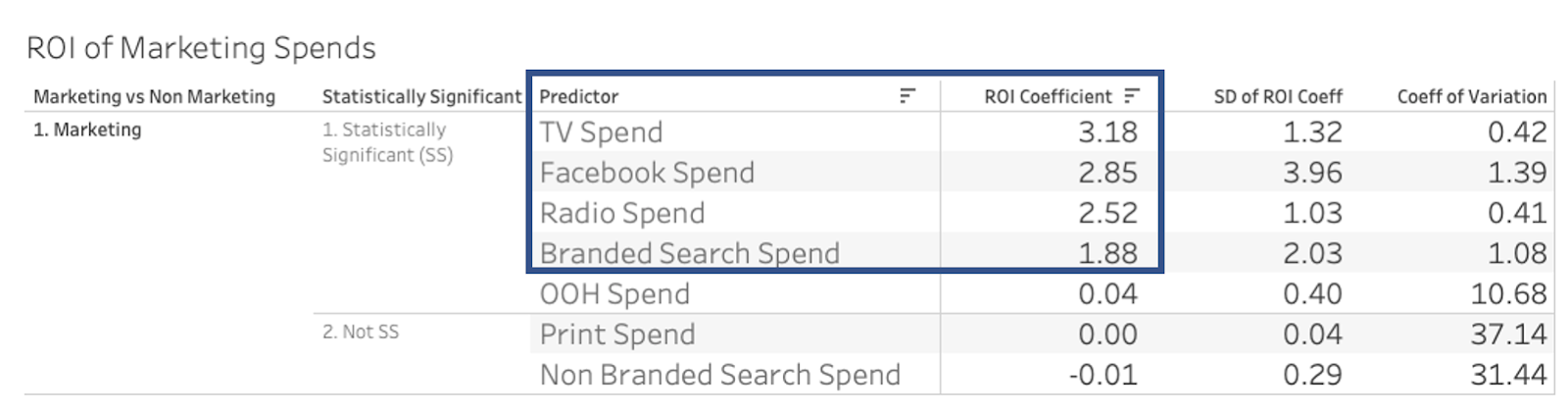
The table below shows us our estimated ROI from the different marketing spends over time. From this table we can see that TV Spend, Facebook Spend, Radio Spend, and Branded Search Spend are estimated to have positive ROI (ROI > 1 is considered to be positive, implying that for every dollar you spend you get > $1 in return).
We define a statistically significant ROI coefficient based on the absolute value of the Standard Deviation / Mean. This is referred to as the Coefficient of Variation. Typically a Coefficient of Variation < 30 is considered to be statistically significant. A literal interpretation from this table is “for every dollar you spend in TV advertising, you are getting $3.18 in sales; for every dollar you spend in Facebook advertising, you are getting $2.85 in sales.” Our model also shows that based on our definition of ROI positive and statistically significant, 4 of 7 marketing channels are both positive and statistically significant.
The ROI coefficients shown in the table are what we use to reconstruct our initial formula. If we recall, previously we stated that:
Sales From Marketing = Sales From Facebook + Sales From Branded Paid Search + …..
A more detailed version of this equation would read:
Sales Due to Marketing = ROI Facebook x FB Spend + ROI Branded Search x BS Spend + …
With these equations in mind, we can now explain both our sales due to non-marketing factors (seasonality, trend, intercept) and our estimated sales due to marketing (Facebook, Branded Search, TV etc). This visual is below:
The top chart shows our estimated sales due to marketing. Each color represents sales due to a different marketing tactic. Similarly, the bottom chart shows sales to do non-marketing where the different colors represent different trends and seasonalities in our dataset. A more rigorous analysis would aim to trace these seasonalities back to factors that are likely to affect your line of business (macroeconomic conditions, changes in distribution, weather etc). Do you know how much your sales increase/decrease when the average daily temperature increases or when the price of a barrel of oil decreases? Media Mix Modeling has the ability to uncover this as well! In the next visual, we will dive directly into our sales due to marketing. As a reference, we can even compare the estimated sales due to marketing with our actual marketing spends.
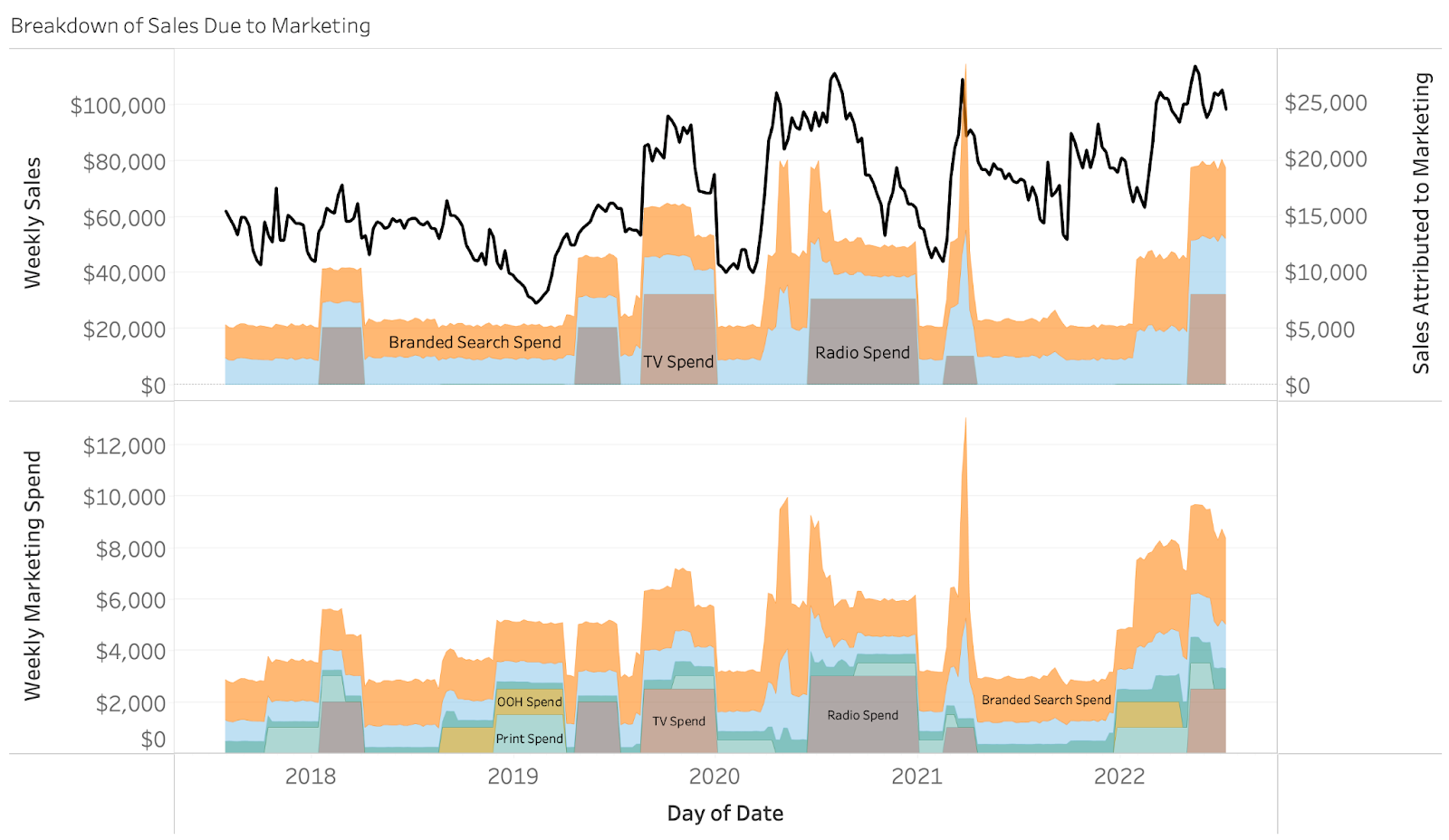
The visual above reveals many details of our analysis, including:
- Weekly Sales (black line top chart)
- Sales Attributed to Marketing (area chart top)
- Weekly Marketing Spends (area chart bottom right)
A quick look at our visual and we can see that weekly marketing spends range between $2k – $12k and are netting estimated returns in sales between $5k – $25k. As a reference, our weekly sales are between $28k and $111k. Notice how during certain timeframes a surge in spending for a particular channel lines up with a surge in sales. An example of this is seen specifically for branded search during the timeframe February, 16 2020 – April, 17 2022 as shown below.
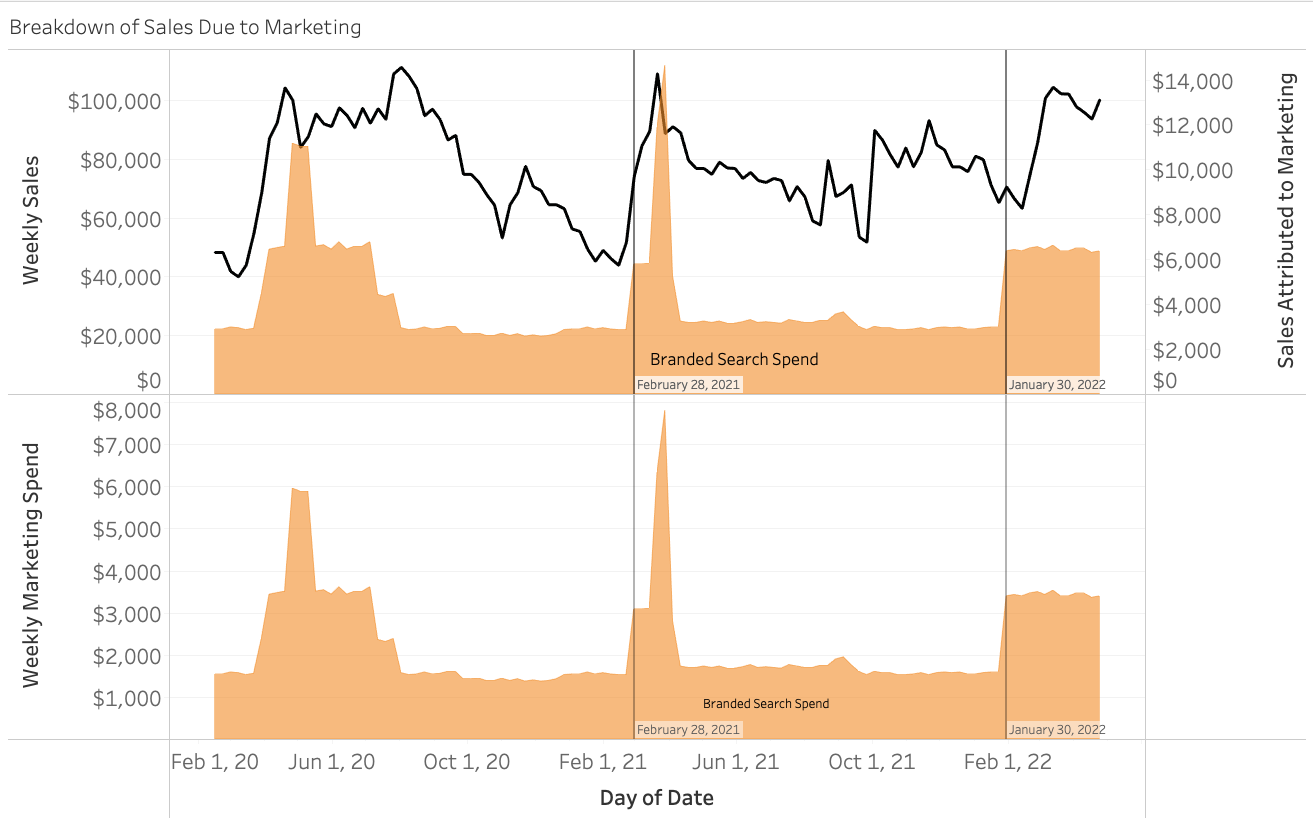
If we look closely, we can see that our increases in Branded Search Spend on February 28, 2021 and January, 30, 2022 line up with increases in sales. These types of patterns are how our model is able to estimate the ROI of our different marketing spends, and a good example of why constant testing and fluctuations in spend should be an essential part of your marketing strategy!
How do you productionise Marketing Mix Modeling (MMM)?
From this analysis, we are able to learn that TV Spend, Facebook Spend, Radio Spend, and Branded Search Spend are positive and statistically significant drivers of sales and OOH, Print Spend, and Non-Branded Spend are not. A natural takeaway from this would be to reduce spending for Print and Non-Branded and increase spending for TV, Facebook, Radio, and Branded. Perhaps, at this point you are thinking, “I should spend all of my money on TV Spend.” It is important to remember that this analysis is called Media MIX Modeling because we are modeling the mix of media spending. The results of this analysis do not neccesarily mean that we would advocate for abandoning spend in channels where we were not able to measure statistically significant positive ROI, nor do they mean we would advocate for going “all in ” on our most effective channel. Instead, we would advocate for strategic adjustments to budgets based on the findings of our model and continued testing of the resulting effects on sales.
https://youtu.be/W8RgYJ0ztN0