

This article data science blogthon.
prologue
Controlling the flow of information from a source system, such as a data warehouse, to a destination system is an essential part of any business seeking to create value from raw data. Data pipeline architecture is a complex task. This is because some problems can occur during transmission. Data sources can create duplicates, errors can propagate from source to destination, and data can become corrupted.
More data and resources can make the process more complex. This is where data feeds come into play. Data pipeline automation simplifies data flow by eliminating manual extraction, transformation, and loading steps and automating the process.
This article describes data pipeline architecture and why you should plan ahead of your integration project. Next, we will discuss the basic parts and processes of the data channel. Finally, we will discuss two examples of data pipeline architectures and discuss one of the best data pipeline tools.
Data pipeline architecture
Architecture is the arrangement of objects that extract, condition and transfer data to appropriate systems to obtain valuable information.
Data pipeline is a broader term, unlike big data pipelines and ETL pipelines, which involve extracting data from sources, transforming it, and loading it into target systems. This includes Big Data and his ETL pipeline as a subset.
The fundamental difference between ETL and data pipelines is that the latter uses processing tools to move data from one system to another, regardless of whether the data is transformed.
- throughput: This is the rate at which data in the pipeline is processed in a given amount of time.
- reliability: Various systems in the data pipeline must be fault tolerant. Trusted channels therefore incorporate auditing, verification, and logging systems to ensure data quality.
- Latency: See how long it takes for one unit of data to pass through the data channel. It’s basically about response time, not throughput.
The need for data pipelines
With massive amounts of data flowing every day, analytics and reporting are enhanced with a streaming data pipeline architecture that allows all data to be processed in real time. Data feeds make data more targeted by making it available for insight into functional areas. For example, a data ingestion channel transfers information from various sources into a centralized data warehouse or database. It helps you analyze data related to targeted customer behavior, process automation, buyer journeys, and customer experience.
Data pipelines send data in chunks designed for specific organizational needs, so you can gain insight into immediate trends and insights to improve business intelligence and analysis.
Source – medium.com
Another key reason data pipelines are essential to your business is to integrate data from multiple sources for comprehensive analysis, reducing the effort spent on analysis and providing only the information your team or project needs. to provide.
Additionally, secure data feeds help administrators restrict access to information. You can grant access only to the data necessary for internal or peripheral team goals.
Data pipelines also mitigate vulnerabilities at many stages of data collection and movement. Copying or moving data through different systems requires moving it between repositories, reformatting it for each system, and integrating it with other data sources. A well-designed streaming data pipeline architecture combines these small parts to create an integrated system that delivers value.
Basic parts and processes of the data pipeline architecture
Data channel design can be divided into the following parts:
source of information
The data ingestion pipeline architecture component helps ingest data from sources such as relational DBMSs, APIs, Hadoop, NoSQL, cloud sources, open sources, data lakes, and data repositories. After fetching data, security protocols and best practices should be followed for optimal performance. and consistency.
extract
Some fields may contain individual elements, such as postal codes for address fields or large collections of values such as business categories. Data extraction works if you need to extract these discrete values or if you need to mask certain array elements.
joint
As part of data pipeline architecture design, it’s common to combine data from different sources. Joins define the logic and criteria for how data is grouped.
Standardization
Data often needs to be standardized by field. This is done using codes related to units of measurement, data, elements, colors or sizes, and industry standards.
repair
Datasets often contain errors such as invalid fields such as state abbreviations or nonexistent postal codes. Similarly, the data may contain corrupted records that need to be deleted or modified by another process. This step in the data pipeline architecture modifies the data before loading it into the target system.
data load
After data is modified and ready for loading, it is moved from where it is used for analysis and reporting to integrated systems. The target system is typically a relational DBMS or data warehouse. Each target system requires the following best practices for good performance and consistency:
automation
Data feeds are typically implemented multiple times on a schedule or on an ongoing basis. Scheduling various processes requires automation to reduce errors and pass status to monitoring procedures.
tracking
As with any system, the individual steps involved in data channel design should be comprehensively investigated. Without monitoring, it is impossible to properly determine if the system is behaving as expected. For example, you can measure when a particular job is started and stopped, total execution time, completion status, and associated error messages.
Data channel architecture example
The two most important examples of big data pipelines are:
Batch data pipeline
Batch processing involves processing blocks of data that have been stored for a period of time. For example, a major financial company processing all his transactions in a month.
Batch processing is suitable for large amounts of data that need to be processed without the need for real-time analysis. Gaining comprehensive insights with batch data feeds is more important than faster analytical results.
In batch data pipelines, source applications such as point-of-sale (POS) systems can generate a large number of data points that need to be transferred to data warehouses and analytical databases.
The diagram below shows how the batch data channel works.
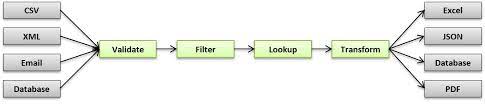
Source – medium.com
streaming data pipeline
Perform data manipulation in real time and motion. You can quickly grasp the situation in a short time after data acquisition. As a result, the data produced can be fed into analytical tools for rapid results.
Streaming data channels process data from POS systems during production. The data stream processing engine sends the output from the data pipeline to data warehouses, marketing applications, CRMs, and several other applications and back to the POS system.
Below is an example of how the data streaming system works.
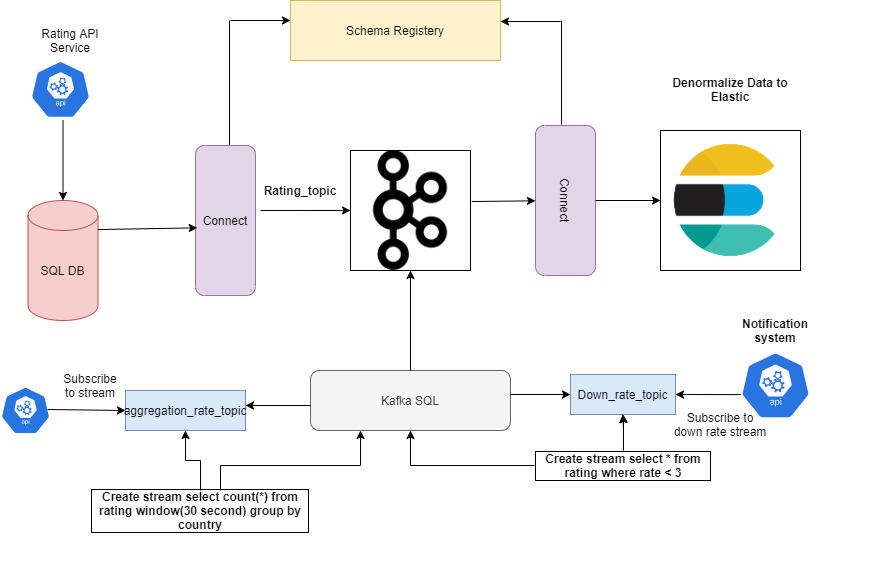
Source – medium.com
Conclusion
A raw data set contains data points that may or may not be relevant to your business. A data pipeline architecture uses a variety of software technologies and protocols to consolidate and manage critical business information, simplifying reporting and analysis.
- Many options are available for building a data pipeline architecture that simplifies data integration. One of the best pipeline automation tools is Astera Centerprise 8.0. It helps you extract, clean up, transform, integrate, and manage pipelines without writing a single line of code.
- Data pipeline is a broader term, unlike big data pipelines and ETL pipelines, which involve extracting data from sources, transforming it, and loading it into target systems. This includes Big Data and his ETL pipeline as a subset.
- Batch processing is suitable for large amounts of data that need to be processed without the need for real-time analysis. Gaining comprehensive insights with batch data feeds is more important than faster analytical results.
Media shown in this article are not owned by Analytics Vidhya and are used at the author’s discretion.