

This article data science blogthon.
prologue
Sentiment analysis is the key to determining the sentiment of reviews sent by customers. Sentiment analysis is mainly used on e-commerce platforms and any platform that requires customer opinion to let people express their experience with the product or thing. Here we demonstrate sentiment analysis on the Flipkart dataset.
Flipkarte is the best way to serve people.
Product review future customers and e-commerce platform sentiment analysis. E-commerce companies can use sentiment analysis techniques to improve their products and customer service. Sentiment analysis also helps companies understand their products better and make further plans around them.

Library import
Practice is done using the Python language and implementation Google joint research Note.
First, we need to import the following libraries:
- Pandas: Data processing of CSV files (e.g. pd.read_csv)
- Seaborn: visualization of statistical plots
- Matplotlib: plotting graphs
- NLTK: Natural Language Processing Toolkit Library for NLP Tasks
- WordCloud: Used for visualizing text data. A large font means that a particular word is used frequently.
- Regular expression (re): RegEx. Used for pattern matching to better understand product reviews.
- nltk Sentiment Vader: Sensitive to polarity (positive, negative, neutral) and intensity (strength of emotion) for the purpose of sentiment analysis.
- Stopwords: Known as commonly used words such as a, an, the, it.
Python code:
About sentiment analysis datasets
The dataset consists of customer reviews of products purchased from Flipkart. The review given is an experience of a product that a customer has purchased through her Flipkart and rated that product.
of data set Flipkart contains three columns.
- Product_name: Product name and details.
- Review: Review what the customer has provided for the product.
- Rating: A range of 1 to 5 stars given by the customer.
data = pd.read_csv("/content/flipkart_reviews.csv")
data.head(10)

Check for null values
Null values can affect the overall shape of the dataset and can affect sentiment analysis. I need to check if my dataset contains null values. To do so,
data.isnull().sum()
If there are no null values in the dataset, the sentiment analysis task will start. The review column needs to be cleaned and prepared for further sentiment analysis.
Data cleaning in sentiment analysis
Data cleaning for review columns is done using regular expressions, stemming, and stopwords. Here, stemmar is simply stemming, converting words to root forms. Applying simple stemming reduces words to their base forms so that similar words are under the same roof. This helps the algorithm to better understand the text data (for example, swim, swim, swimming reduces to swim, where the word swim is the etymology). SnowballStemmar is a stemming algorithm that runs on top of Porter Stemmar. It also uses regular expressions to check if a string contains a specific search pattern.
stemmer = nltk.SnowballStemmer("english")
stopword=set(stopwords.words('english'))
def clean(text):
text = str(text).lower()
text = re.sub('[.*?]', '', text)
text = re.sub('https?://S+|www.S+', '', text)
text = re.sub('+', '', text)
text = re.sub('[%s]' % re.escape(string.punctuation), '', text)
text = re.sub('n', '', text)
text = re.sub('w*dw*', '', text)
text = [word for word in text.split(' ') if word not in stopword]
text=" ".join(text)
text = [stemmer.stem(word) for word in text.split(' ')]
text=" ".join(text)
return text
data["Review"] = data["Review"].apply(clean)
After cleaning the data, we need to see how most people rate products purchased from Flipkart. Ratings range from 1 to 5.
ratings = data["Rating"].value_counts() numbers = ratings.index quantity = ratings.values
After counting the total number of each rating, you can go further and plot the ratings in the form of a pie chart to get a visual representation and percentage of each rating category.
figure = px.pie(data, values=quantity, names=numbers,hole = 0.5) figure.show()
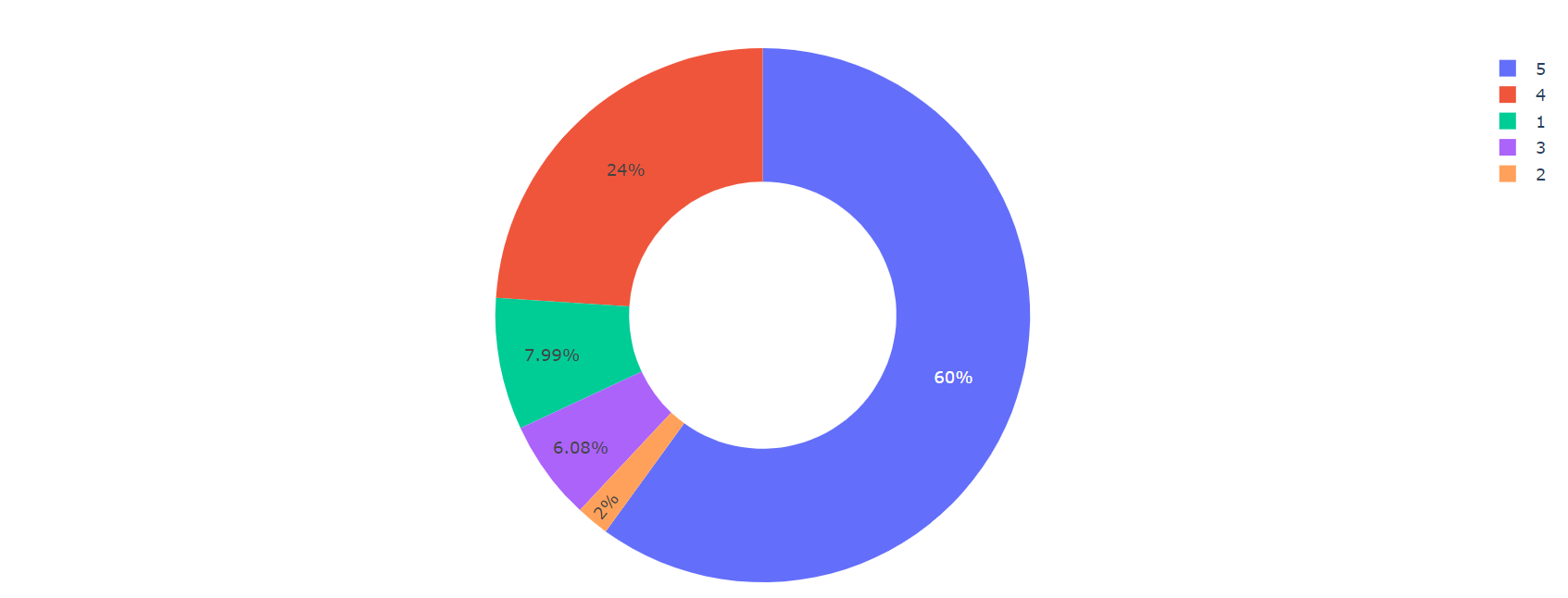
Product review rating
Therefore, the pie chart shows that 60% of people gave a 5 out of 5 rating to products purchased from Flipkart, with a 2 star rating being the lowest customer rating.
word cloud
Now let’s take a look at the most common or frequent words customers use to give product reviews. Visualized in font. This is used for the review column. WordCloud visualizes data in a textual representation.
WordCloud displays the most frequently used or important words in a larger font size and less frequently used words in a smaller font size. The code-out output below shows that words like good, phone, and best are used most often, so the font size is large, and words like design, camera, etc. are displayed in a smaller font size.
text = " ".join(i for i in data.Review)
stopwords = set(STOPWORDS)
wordcloud = WordCloud(stopwords=stopwords,
background_color="white").generate(text)
plt.figure( figsize=(15,10))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()
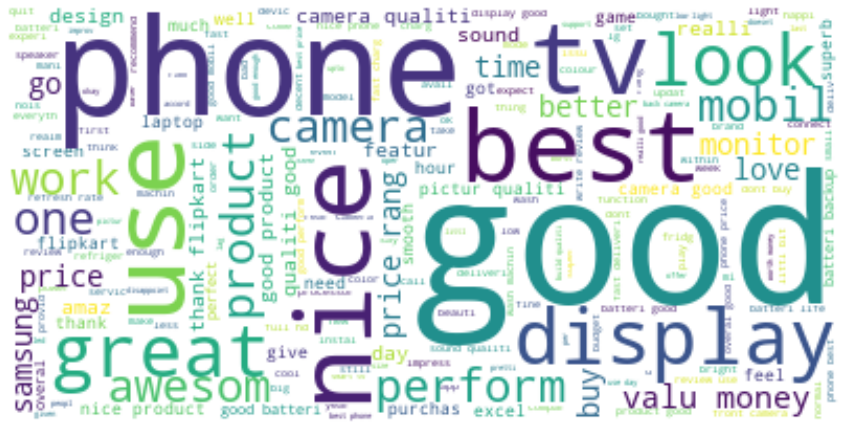
Word cloud visualization
sentiment analysis
For sentiment analysis, we’ll calculate a sentiment score for each review. With this help, you can find out what that review really means, helping future customers and companies who are willing to buy the product understand the product.
1. Add Column
First, add three columns to your dataset: positive, negative, and neutral. This will calculate a sentiment score for each review. This will print all rows of the dataset and execute. The code below analyzes only the Review column and displays the sentiment score for each row. SentimentIntensityAnalyzer() looks at text and detects whether a given text review portion is positive, negative, or neutral. Also, the reputation score is determined based on the polarity score which determines which category the review belongs to.
sentiments = SentimentIntensityAnalyzer() data["Positive"] = [sentiments.polarity_scores(i)["pos"] for i in data["Review"]] data["Negative"] = [sentiments.polarity_scores(i)["neg"] for i in data["Review"]] data["Neutral"] = [sentiments.polarity_scores(i)["neu"] for i in data["Review"]] data = data[["Review", "Positive", "Negative", "Neutral"]] data.head()
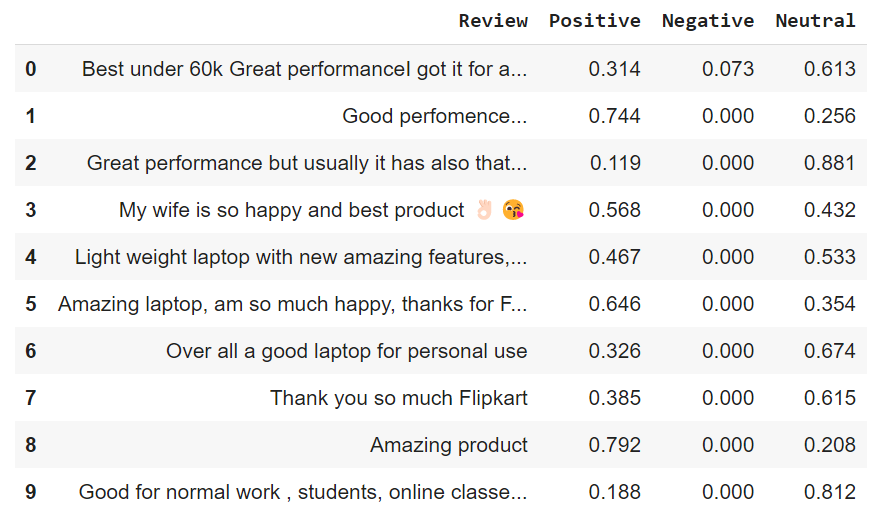
The output above represents the sentiment score for each row.
2. Product reviews
After creating our column, let’s see what most reviewers think about the products and services they’ve purchased from Flipkart. Execute a conditional block to determine the overall sentiment score for the entire dataset.
x = sum(data["Positive"]) y = sum(data["Negative"]) z = sum(data["Neutral"])
def sentiment_score(a, b, c):
if (a>b) and (a>c):
print("Positive 😊 ")
elif (b>a) and (b>c):
print("Negative 😠 ")
else:
print("Neutral 🙂 ")
sentiment_score(x, y, z)
3. Emotional state
After running the above lines, the generated output shows that most reviews are in a neutral state. Now let’s calculate the positive, negative, and noi sentiment scores for each review category.

4. Sentiment score
Then, branch out the sentiment scores for positive, negative, and neutral reviews to get an accurate count of reviews for each category. The code below will output the total number of reviews in each of the positive, negative, and neutral categories.
print("Positive: ", x)
print("Negative: ", y)
print("Neutral: ", z)

Conclusion
So in the output above, there are 923.55 positive reviews, 96.77 negative reviews, and 1283.68 neither reviews. In the final output of the whole implementation, the important points can be stated as follows.
- Most reviews favor Neutral.
- A small percentage of negative review scores and moderate positive reviews.
- Therefore, with the help of the above sentiment analysis implementation, we can conclude that most people are satisfied with the products and services they receive from Flipkart.
- This shows that sentiment analysis is a great process for gathering insights about each product, which ultimately benefits current and future customers and e-commerce companies.
- Sentiment analysis is important. Because, based on bad reviews, e-commerce companies improve those products or replace them with new, better products, which ultimately improves overall customer service.
Media shown in this article are not owned by Analytics Vidhya and are used at the author’s discretion.